
眼动追踪越发成为头显的标准配置,各家厂商都在积极探索精确、轻型、紧凑和高成本效益的眼动追踪系统。早前映维网已经分享了一系列与所述主题相关的厂商发明,而美国专利商标局日前又公布了一份名为“Distributed sensor module for eye-tracking”的Meta专利申请。
对于眼动追踪,其中一个挑战是需要将功耗降到最低,从而优化可穿戴设备的形状参数设计和续航能力。一种降低功耗的方法是利用机器学习来执行目标追踪,但所述方式需要一个大型网络,而这不可避免地会产生功耗,并且不能提供足够精确的结果。
为了解决上述问题,Meta希望通过一个分布式设置来减少功耗,并提供足够精确的结果。简单来说,可以由头显搭载一个传感器模块,并由在与头戴式设备分离的本地计算设备中实现一个中央模块。然后,传感器模块来检测来自下采样图像的特征,从而执行对象追踪,而中央模块可处理传感器模块的任何潜在请求/服务。
所述分布式传感器模块包括摄像头、存储单元、检测单元和计算单元,并用于通过机器学习模型从下采样的图像中有效地检测特定特征。以所述方式,传感器模块可以生成/计算特定于特征的图像,无需过度读取图像中的片段并降低功耗。
在一个实施例中,摄像头配置为捕捉描绘用户眼睛的一个或多个用户图像,存储单元配置为存储图像,检测单元可以从下采样版本的图像中检测包括用户眼睛特征的一个或多个第一片段,并从存储单元读取与下采样版本图像中的第一片段相对应的一个或多个图像中的一个或多个第二片段。然后,计算单元可以基于包括图像中眼睛特征的第二片段来计算用户的注视点,而不搜索原始图像中每个片段中的特征(这需要额外的时间和能力来从原始图像读取/检测每个片段)。因此,所述传感器模块可以在一定程度降低功耗。

图1示出了具有bounding box110和分割遮罩120的图像100。在特定实施例中,机器学习模型接受训练以处理图像(例如图像100),并检测图像中的特定对象。在所述示例中,机器学习模型经过训练以识别人的特征。在特定实施例中,机器学习模型可以输出包围检测到的对象类型实例(例如人)的bounding box110。矩形bounding box可以表示为四个二维坐标,并表示框的四个角。在特定实施例中,机器学习模型可以附加地或可选地输出识别属于所检测实例的特定像素的分割遮罩120。例如,分割遮罩120可以表示为二维矩阵,每个矩阵元素对应于图像的像素,而元素的值对应于关联像素是否属于检测目标。
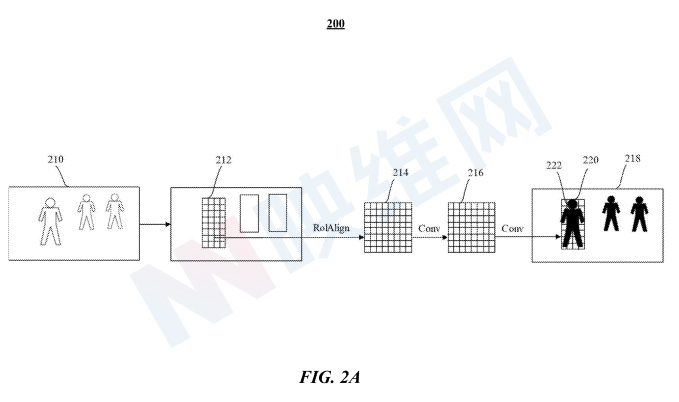
图2A示出了机器学习模型200的架构。机器学习模型200配置为将图像210或图像的预处理表示作为输入,例如三维矩阵,其尺寸对应于图像的高度、宽度和颜色通道,比方说红色、绿色和蓝色。机器学习模型200识别包围图像210中的目标对象(例如人)的bounding box212。另外,机器学习模型200配置为读取图像210的下采样版本(例如下采样图像218)中的bounding box220中的片段222,并检测作为与图像210中的bounding box212中的目标对象对应的目标区域(RoI)的区段222。在特定实施例中,RoI可包括人、汽车或任何其他类型的对象。
在一个实施例中,可以通过任何可操作的计算机视觉技术来检测下采样图像218中的RoI。例如,包括RoIWarp for RoI pooling或RoaAign的Mask R-CNN可以处理图像210以确定作为RoI的bounding box212,并通过使用ROAlign经由卷积层214、216将图像210中的bounding box212映射到特征映射(例如下采样图像218中的bounding box220对应于图像210中的bounding box212),将图像210卷积到下采样图像218中,并在图像210中输出与bounding box212中的特征对应的分割遮罩。
在特定实施例中,机器学习模型200配置为输出对象检测(例如围绕人的边界框的坐标)、关键点(例如代表被检测人的姿势)和/或分割遮罩(例如识别对应于被检测人的像素)。在特定实施例中,每个分割遮罩具有与输入图像(例如图像210)相同数量的像素。在特定实施例中,分割遮罩中对应于目标对象的像素标记为“1”,其余像素则标记为“0”,以便当分割遮罩覆盖在输入图像上时,机器学习模型200可以有效地选择与捕获图像中的目标对象相对应的像素,例如包括图像210中用户特征的区段。
Meta指出,机器学习模型的200架构旨在降低复杂性,从而减少处理需求,以在资源有限的设备产生足够精确和快速的结果,并满足实时应用的需求,例如每秒10、15或30帧。与基于ResNet或Feature Pyramid Networks(FPN)的传统架构相比,机器学习模型200要小得多,并且可以更快地生成预测,例如大约快100倍。
所以,这个机器学习模型可用于检测关于用户眼睛的特征(例如用户眼睛的轮廓),以便实时计算用户的注视点。
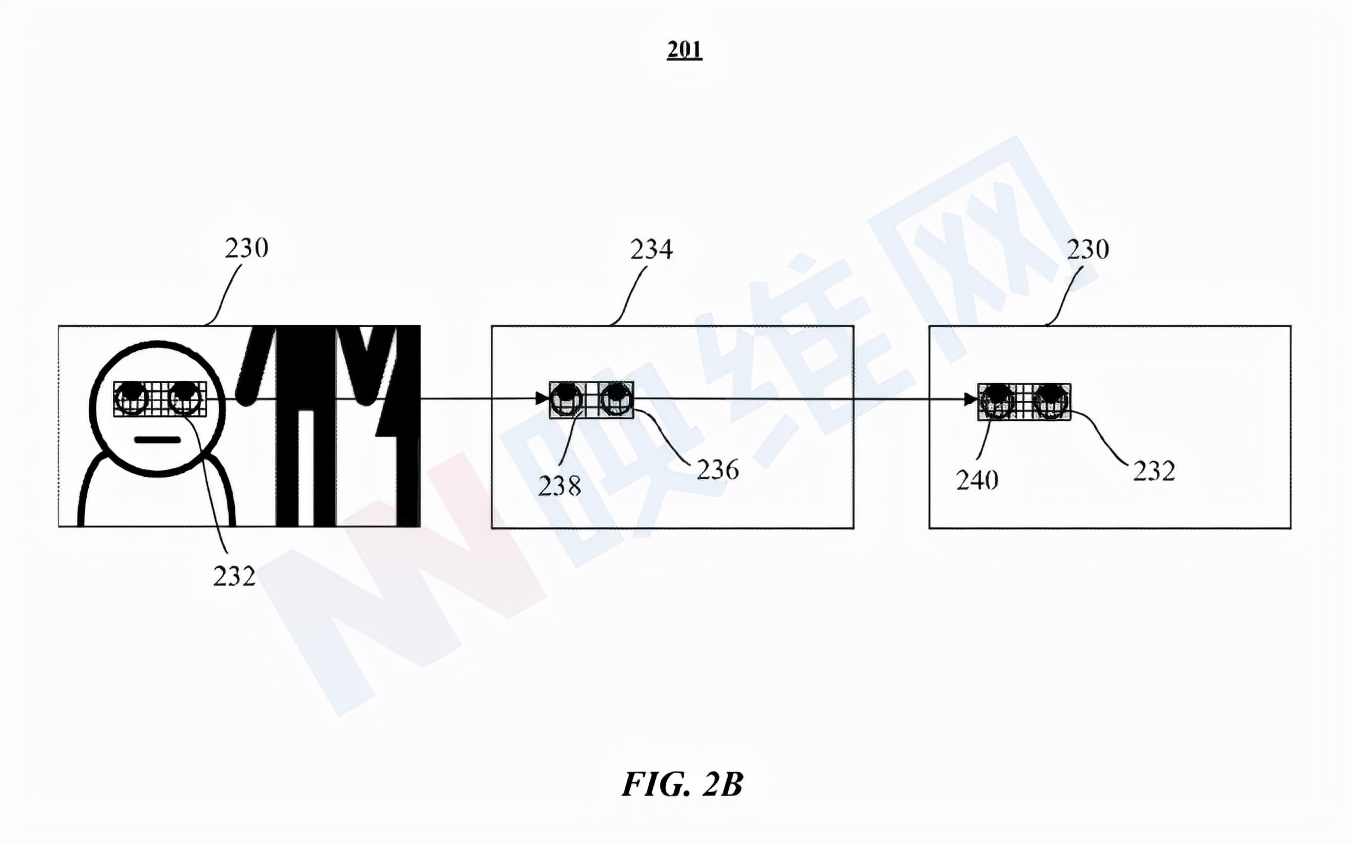
图2B示出了用于预测bounding box、分段遮罩和关键点的机器学习模型201的示例架构。机器学习模型201配置为获取输入图像230,并且通过处理图像230的下采样版本(例如下采样图像234),输出N个区段236。其中,区段236是下采样图像234中的RoI。在特定实施例中,RoI是用户的眼睛特征/关键点,例如,用户眼睛的轮廓、虹膜的边缘和/或用户眼球中的反射。
在图2B中,输入图像230包括包围用户眼睛特征并由一个或多个区段组成的bounding box232。机器学习模型201处理输入图像230的下采样版本(例如下采样图像234),并读取下采样图像234中对应于输入图像230中的bounding box232的bounding box236中的区段,以检测包括目标眼睛特征的一个或多个第一区段238。因此,当需要计算用户的注视点时,用机器学习模型201实现的追踪系统可以直接读取/检索输入图像230中与在下采样图像234中用眼睛特征识别的第一区段238相对应的区段240。
在特定实施例中,输入图像230可存储在存储器或任何存储设备中,这样,可以简单地从存储器选择性地读取下采样图像234和描绘眼睛特征的全分辨率图像的部分(例如下采样图像234的至少一部分),从而最小化消耗大量功率的存储器访问。
在特定实施例中,机器学习模型200、201可包括若干高级组件以检测bounding box、关键点和分割掩码。组件中的每一个都可以配置为神经网络。从概念上讲,机器学习模型200、201在所示架构中配置为处理输入图像并准备表示图像的特征映射,例如卷积输出的起始。RPN获取由神经网络生成的特征映射,并输出N个可能包括感兴趣对象的拟议RoI。
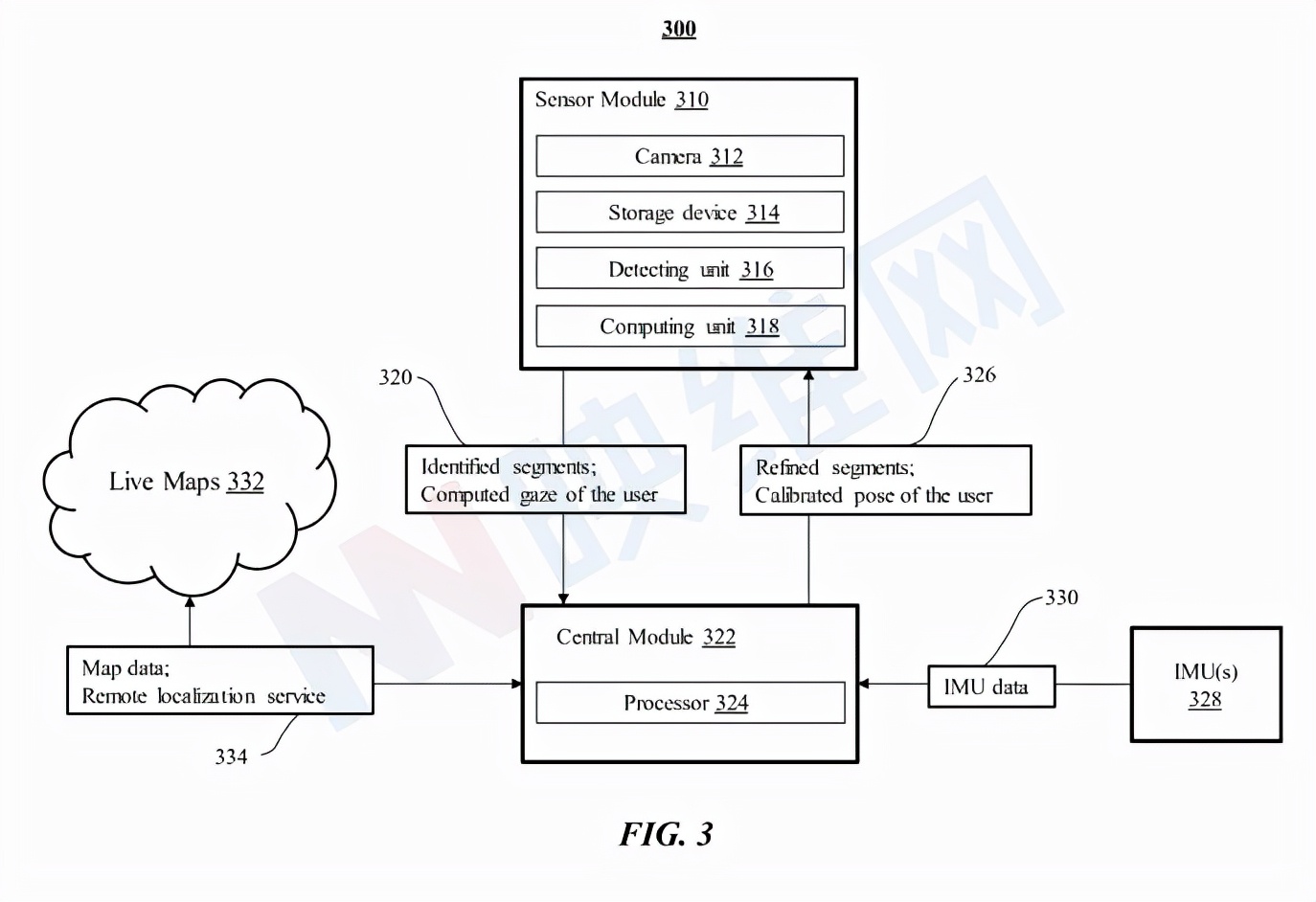
图3示出了根据追踪系统架构。追踪系统300包括至少一个传感器模块310和中央模块322。传感器模块310包括至少一个摄像头312,其捕捉用户的一个或多个图像,而图像可以是描绘用户眼睛特征的用户的一系列帧。传感器模块同时可以包括存储用户捕捉的图像的存储单元314和检测单元316,后者利用机器学习模型来实现,以在捕获图像的下采样版本中检测包含用户眼睛特征的区段。传感器模块同时包括计算单元318,其基于与捕获图像的下采样版本中的检测片段相对应的捕获图像中的片段来计算用户的注视点。
另外,中央模块322包括至少一个处理器324,处理器324进一步处理来自传感器模块310的捕获图像320中的用户的计算注视点和识别片段。中央模块进一步包括来自一个或多个IMU 328的惯性测量单元(IMU)数据330,所述惯性测量单元(IMU)数据330在带有传感器模块310的头戴式设备中实现。例如,中央模块322基于所拍摄图像的所识别片段中的特征,以及从IMU 328发送的IMU数据330中提供的camera姿势、速度、加速度和运动来估计用户的状态,另外,中央模块322可以利用用户的状态来细化捕获图像中的片段,并将用户326的细化片段/注视点提供给传感器模块310。
在特定实施例中,中央模块322可以为用户320的计算注视执行广泛的服务,以降低功耗,例如在本地或全局定位用户/设备(例如远程定位服务334)。在特定实施例中,中央模块322处理来自IMU 328的IMU数据330,以提供用户的预测姿势并帮助生成用户的状态。在特定实施例中,如果需要,中央模块322可以通过基于从传感器模块310发送的捕获图像320中的识别片段中的特征检索实时映射332来定位传感器模块310。实时映射332包括用于用户/传感器模块310的定位的映射数据334。中央模块322可以校准用户在映射数据334的姿势,并将用户326的校准姿势提供给传感器模块310。在特定实施例中,中央模块322可以包括存储设备,其用于存储捕获的图像和/或用户的计算注视点,以减轻传感器模块310的重量。
在特定实施例中,传感器模块310可在头戴式设备中实现,而中央模块322可在与头戴式设备分离的本地计算设备实现。如在两部分系统中。头戴式设备包括一个或多个处理器,配置为实现传感器模块310的摄像头312、存储设备314、检测单元316和计算单元318。在一个实施例中,每个处理器被配置为分别实现摄像头312、存储设备314、检测单元316和计算单元318。本地计算设备包括配置为执行中央模块322的一个或多个处理器。
一种基于机器学习(ML)的轻型眼动追踪系统可以分阶段执行,以最小化功耗。执行眼动追踪系统以对传感器模块捕获的图像进行下采样,从下采样图像中识别目标片段(例如,基于眼睛轮廓),基于识别的片段加载高分辨率图像的目标区域,以及基于高分辨率图像(例如最初捕获的图像)的RoI中的反射/折射计算注视点。眼动追踪系统仅检索高分辨率图像的RoI,所以可以减少内存访问和功耗。
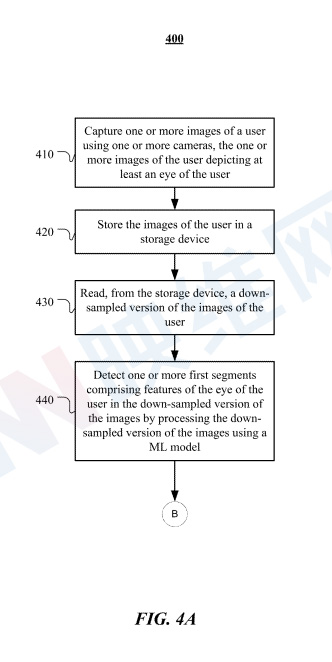
图4A示出了传感器模块处检测特征片段的示例方法400。方法400可以从步骤410开始:使用一个或多个摄像头捕捉用户的一个或多个图像,用户的一个或多个图像描绘了用户的至少一只眼睛。在特定实施例中,用户的一个或多个图像包括从一个或多个摄像头的一个或多个视角捕获的不同注视方向,从而确定用户的注视点。
在步骤420,方法400可以将用户的一个或多个图像存储在存储单元中。在特定实施例中,存储单元可以在具有一个或多个摄像头的头戴式设备中实现。
在步骤430,方法400可以从存储设备读取用户的一个或多个图像的下采样版本。
在步骤440,方法400可以通过使用机器学习模型处理一个或多个图像的下采样版本,在一个或多个图像的下采样版本中检测包含用户眼睛特征的一个或多个第一区段。在特定实施例中,一个或多个第一区段包括用户眼睛轮廓的至少一部分。
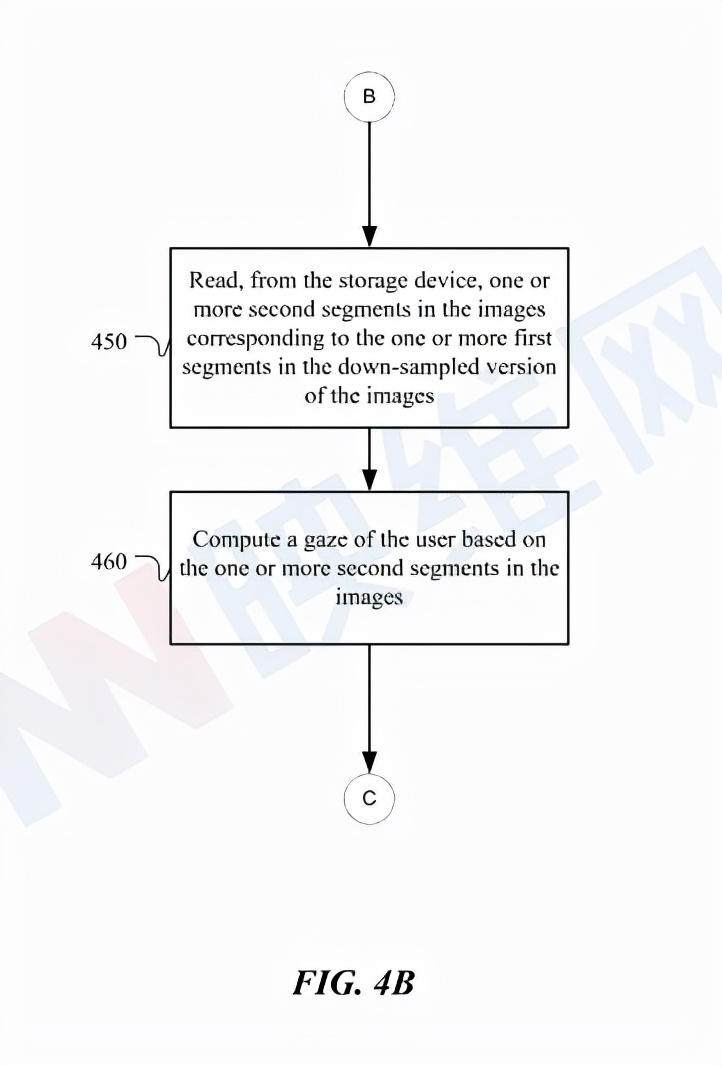
图4B的示例方法401通过读取与传感器模块处下采样图像中检测到的区段相对应的图像中的区段来计算用户的注视点。方法401可以在方法400中的步骤440之后的步骤450开始:从存储单元读取与一个或多个图像的下采样版本中的一个或多个第一区段相对应的一个或多个图像中的一个或多个第二区段。在特定实施例中,一个或多个第二区段包括用户眼睛中的反射和/或折射。在特定实施例中,一个或多个第二区段包括至少一个注视方向。
在步骤460,方法401可以基于一个或多个图像中的一个或多个第二区段来计算用户的注视点。
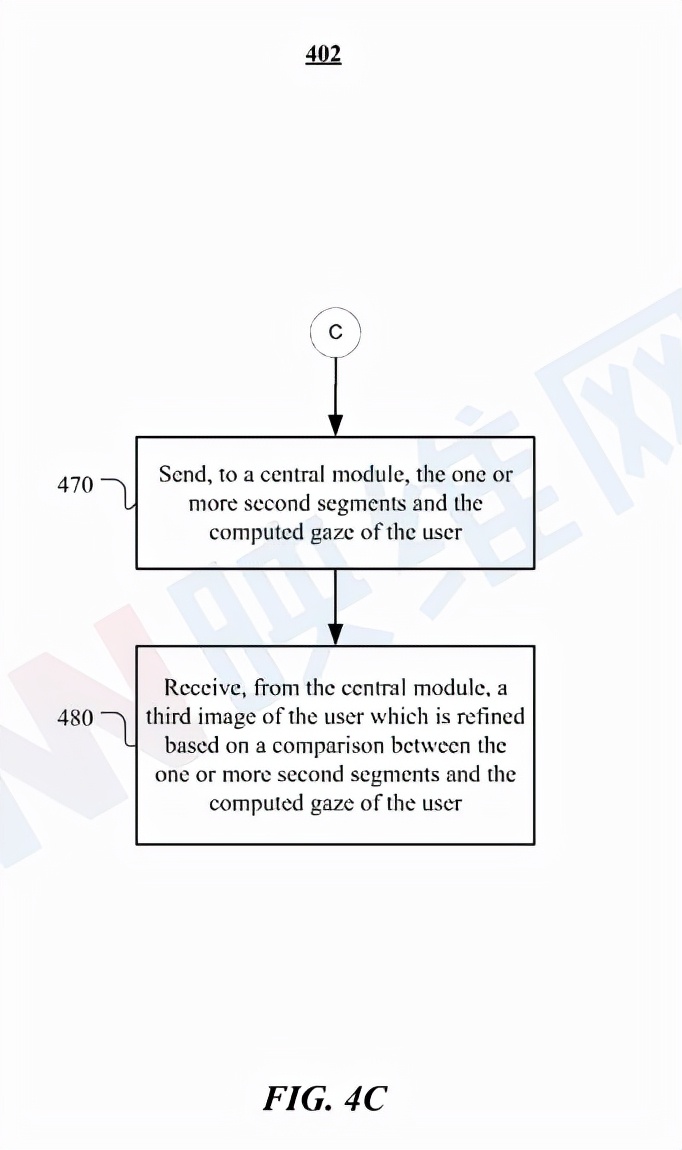
图4C示出了在中央模块处理的图像细化示例方法402。在方法401中的步骤460之后的步骤470,方法402可以开始向中央模块发送一个或多个第二区段和用户的计算注视点。
在步骤480,方法402可以从中央模块接收用户的第三图像,所述图像基于一个或多个第二片段与用户的计算注视点之间的比较而实现细化。在特定实施例中,中央模块可以在与头戴式设备分离的本地计算设备中实现。中央模块可处理传感器模块的任何潜在请求/服务,以降低功耗。
相关专利:Facebook Patent | Distributed sensor module for eye-tracking
名为“Distributed sensor module for eye-tracking”的Meta专利申请最初在2020年8月提交,并在日前由美国专利商标局公布。
